How does BERT model work?
Written on May 3rd , 2021 by szarki9
Hi All!
It has been a while since I did post something here, but this year was extremely busy as I was in the process of obtaining my master's degree! So with a lot more knowledge, and experience, I can share here some nicer and more advanced content 😊.
Lately, I am working on my Master's Thesis and I am researching the NLP area. Today I would like to summarize the BERT method [1], how does it work, and how it can be used for downstream tasks.
What was so novel about BERT and how is BERT pre-trained?
Let’s start with existing strategies for applying pre-trained language representations to downstream tasks. First of all, we can do it either by feature-based approach or by fine-tuning. The feature-based approach (example: ELMO [2]) uses pre-trained language representations as additional features and includes them in the task-specific architecture. On the other hand, the fine-tuning approach fine-tunes minimal and primarily introduced parameters for some specific tasks and datasets (example: Open AI GPT[3]). BERT is the model that is intended for use as a part of the latter one and was invented to overcome the major limitation of the unidirectional language models, where e.g. as in Open AI GPT unidirectional means that model architecture reads sentences from left to right, and then every token can only be corresponded or reflected in the model by the previous tokens. BERT introduced by Google in 2018 uses two tasks to train its language representation, and thanks to them it preserves the bidirectionality within interpreting the data, which overcomes the limitations of unidirectional models. The two tasks that are being used for BERT pre-training are:
1. masked language model (MLM) – where model randomly masks some of the tokens from the input and then tries to predict the original vocabulary id of the masked word based on its context (reading text in that way enables to make use of the accessing the text both ways -> bidirectional transformer), 15% of the tokens were masked here, and then prediction was done using softmax function applied to all of the vocabulary.
2. (binarized) next sentence prediction (NER) – where having two sentences classification occurs whether sentence A should be followed by the sentence B.
The exact architecture is pictured on the following graph provided by the authors [1]:
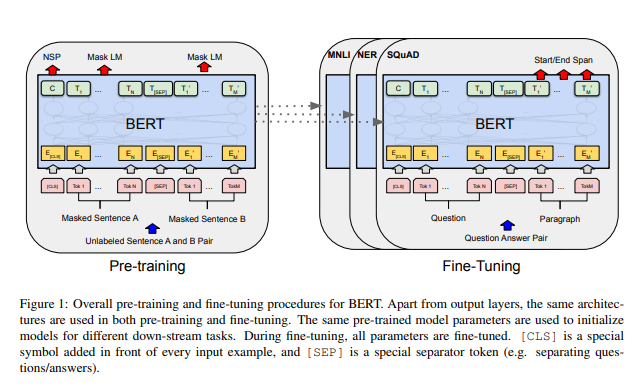
First, we can note several characteristic tokens for BERT. [CLS] – is the first token of every sequence, called special classification token, and later the final hidden state corresponding to this token is used as the aggregate sequence representation for the classification task. [SEP] – is a separate token used to differentiate sentences. For a given token input representation is constructed by summing the corresponding token, segment, and position embeddings (look below [1]).
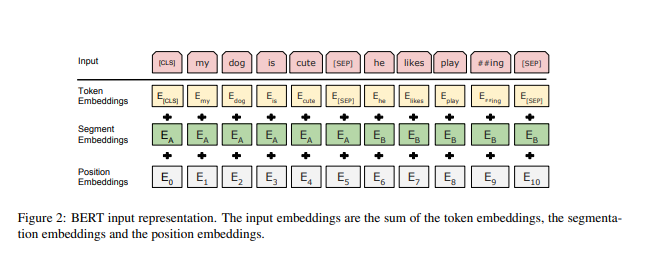
Which datasets were used for pre-training BERT?
BookCorpus (800M words) [4], and English Wikipedia (2500M words) [5], which were extracted with WordPiece embeddings and resulted in the vocabulary of 30k tokens.
Are there BERTs trained on different datasets?
Yes! The most common base for BERT is bert-base-uncased (in huggingface implementation), which is trained as stated above. We can encounter bert-large-uncased as well, and here the dataset used for pre-training was the same, but the difference lays in the number of encoder layers. Also, uncased means that the model does not make a difference between English and english, so it is not sensitive to the capital letters. I was researching mostly scientific bases, so let me introduce them below:
- scibert_scivocab_uncased [6] - same architecture as BERT-base, but trained on 1.14M papers from Semantic Scholar, where 18% papers were from the Computer Science domain, and 82% from the broad biomedical domain,
- BioBERT [7] - the corpus of biomedical research articles was sourced from PubMed3 article abstracts and PubMed Central4 article full texts,
- ClinicalBERT [8] - 2 million notes in the MIMIC-III v1.4 database, uses text from all note types,
- Discharge Summary BERT [8] - 2 million notes in the MIMIC-III v1.4 database, uses only discharge summaries.
But there are plenty more, so whatever is yours needs you to need to research it 😊.
Were there any improvements of BERT during the last 3 years?
Yes! So far many new models were developed, one of them is XLNet [9], which uses the same pre-training data as BERT, but instead of masking 15% of tokens (as it was in BERT) in the MLM task, it introduces permutation language modeling, where all of the tokens are predicted in random order. Also, RoBERTa [10] is the improvement of BERT, in both dataset and also architecture-wise approach. Corpus here was expanded with data from CommonCrawl News, CommonCrawl Stories, and Web text datasets. Also, Next Sentence Prediction task was removed, and dynamic masking was introduced, in which masked tokens are changed with each epoch.
Why BERT is so special?
So now it is considerer to be SOTA (state-of-the-art) model in many downstream applications. And by SOTA we mean here that it can sometimes return accuracy above 90% (!) for a given task, which means that the model is not right relatively rarely 😊. That makes it an extremely powerful tool!
That would be all for now, thanks a lot and speak to you soon!!!
szarki9
P.S some references in the end if you'd like to read about it more:
[1] Devlin, Jacob & Chang, Ming-Wei & Lee, Kenton & Toutanova, Kristina. (2018). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. https://arxiv.org/abs/1810.04805
[2] Peters, Matthew & Neumann, Mark & Iyyer, Mohit & Gardner, Matt & Clark, Christopher & Lee, Kenton & Zettlemoyer, Luke. (2018). Deep Contextualized Word Representations. 10.18653/v1/N18-1202. https://arxiv.org/abs/1802.05365
[3] Radford, A., Narasimhan, K., Salimans, T. and Sutskever, I., 2018. Improving language understanding by generative pre-training. openai-assets/research-covers/language-unsupervised/language_understanding_paper.pdf
[4] Yukun Zhu, Ryan Kiros, Rich Zemel, Ruslan Salakhutdinov, Raquel Urtasun, Antonio Torralba, and Sanja Fidler. 2015. Aligning books and movies: Towards story-like visual explanations by watching movies and reading books. In Proceedings of the IEEE international conference on computer vision, pages 19–27. https://arxiv.org/abs/1506.06724
[5] https://www.english-corpora.org/wiki/
[6] Beltagy, Iz & Cohan, Arman & Lo, Kyle. (2019). SciBERT: Pretrained Contextualized Embeddings for Scientific Text. https://arxiv.org/abs/1903.10676
[7] Lee, Jinhyuk & Yoon, Wonjin & Kim, Sungdong & Kim, Donghyeon & Kim, Sunkyu & So, Chan. (2019). BioBERT: pre-trained biomedical language representation model for biomedical text mining. https://arxiv.org/abs/1901.08746
[8] Alsentzer, Emily & Murphy, John & Boag, Willie & Weng, Wei-Hung & Jin, Di & Naumann, Tristan & McDermott, Matthew. (2019). Publicly Available Clinical BERT Embeddings. https://arxiv.org/abs/1904.03323
[9] Yang, Zhilin & Dai, Zihang & Yang, Yiming & Carbonell, Jaime & Salakhutdinov, Ruslan & Le, Quoc. (2019). XLNet: Generalized Autoregressive Pretraining for Language Understanding. https://arxiv.org/abs/1906.08237
[10] Liu, Yinhan & Ott, Myle & Goyal, Naman & Du, Jingfei & Joshi, Mandar & Chen, Danqi & Levy, Omer & Lewis, Mike & Zettlemoyer, Luke & Stoyanov, Veselin. (2019). RoBERTa: A Robustly Optimized BERT Pretraining Approach. https://arxiv.org/abs/1907.11692
