KG evaluation framework
Written on January 20th, 2024 by szarki9
Hi All!
Long time no see haha. As a part of my 2024 resolutions (or rather goals), I want to pick up writing this blog again! It has been over two years since my last post, and a lot of has happened during that time. First of all, I finished my MSc in Data Science, and I started working as a Data Scientist. I've learned a lot, and also made some (small) contributions to the community 🙂.
And this post is going to be about the contributions - or rather, one of them! I will start with the topic of my MSc Thesis, which I can proudly announce that was published within the workshop proceedings of DeepLearning4KnowledgeGraphs workshop (ISWC 2021 conference).
Here you can find the link to workshop proceedings together with the link to my paper.
I was working on an evaluation framework for Knowledge Representation Quality (so basically on how to evaluate the quality of Knowledge Graphs).
A quick recap on KGs: A Knowledge Graph (KG) is a graph representation of knowledge, with entities, edges, and attributes. Entities represent concepts, classes or things from the real world, edges represent the relationships between entities, and attributes define property-values for the entities. We refer to these sets as "triples".
Motivation behind the work
Knowledge Graphs are at the heart of many data management systems nowadays, with applications ranging from knowledge-based information retrieval systems to topic recommendation and have been adopted by many companies. Our research originated with the need for the automatic quality assessment (QA) of OmniScience, Elsevier’s cross-domain Knowledge Graph powering applications such as the Science Direct Topic Pages.
The contribution
In the work we focus on the semantic accuracy dimension: the degree to which data values correctly represent the real-world facts (or concepts) . We focus on on the hierarchy evaluation of KGs: whether its hierarchical structure is correctly represented. In the work we employ contextual word embeddings and investigate the use KG-BERT method’s binary classification task. It is a binary triple classification task, as for a given KG triple (entity, relation, entity/literal) the classifier will return whether a given triple is correct or not. KG-BERT takes advantage of the textual representation of the data for assessing the veracity of KG triples and uses transfer learning to fine-tune embeddings pre-trained using the BERT model for a triple classification task. Our novel contribution is to use textual representations of the KG hierarchy in combination with KG-BERT to evaluate hierarchy quality. We evaluate the performance of this method on four different KGs.
I won’t be diving in into the related work, you can have a look into the paper!
Datasets
We selected four Knowledge Graphs from different domains (described in more details in Table 1), which are all hierarchical knowledge graph (structured with the classification inclusion relation). We discarded here the benchmark datasets of WN11 and FB13 typically used for triple classification tasks, as they contain a wide variety of relationships and were not representative of our target KGs.
WordNet is a large lexical database representing relationships between words in the English language. It is widely used for tasks such as natural language processing or image classification. We extracted a subset of WordNet focused on the classification inclusion relation: we extracted only nouns - excluding proper names - in a hyponymy relation. We performed this filtering on the hyponymy Wordnet subset.
The Unified Medical Language System (UMLS) is a comprehensive ontology of biomedical concepts. UMLS is made of two distinct KGs: the Semantic Network and a Metathesaurus of biomedical vocabularies. The Semantic Network represents broad subject categories together with their semantic relations. It groups and organizes the concepts from the Metathesaurus in one of the four relationships: "consist of", "is a", "method of", "part of". We selected the Semantic Network for our research because it has more generic concepts than the Metathesaurus and is better structured. We decided to investigate the performance of our model on the subset of that network consisting of the triples in a hierarchical ("is a") relationship (the classification inclusion relation).
OmniScience is an all-science domains knowledge graph that is used, amongst others, for the annotations of research articles. It connects external publicly available vocabularies with the entities required in Elsevier platforms and tools. It is maintained by scientific experts from Elsevier. OmniScience is a poly-hierarchy, in which scientific concepts can belong to multiple domains. The relationship between OmniScience concepts can be described as a hyponymy relation, or "is a" relation. OmniScience has several domain branches, such as Physics, Mathematics, or Medicine and Dentistry. We used two branches as test cases, namely Physics and Mathematics.

Negative Sampling
We considered all of the KGs above to consist of correct triples. Therefore, negative sampling is necessary to prepare a training set for a classification problem. We followed the approach proposed in and use the 1:3 ratio for negative samples. We followed three strategies to generate these negative samples:
- per each head entity we randomly sample a tail entity;
- per each tail entity we randomly sample a head entity;
-
per each pair we exchange the head entity with the tail entity, which gives us “reversed” samples, that should help train the model with respect to the direction of the relation.
After sampling 3 negative examples per each proper pair, we filtered out all of the generated samples did that occur in the original set of triples from KG to ensure that there are not contradictory samples in the training set.
The Method
We propose to use a (binary) triple classification task approach to address the problem of KG hierarchy evaluation. A triple classification task aims to predict whether an unseen Knowledge Graph triple is true or not. For that we can consider KGs entities and their relationships as real-valued vectors, and assess the triples plausibility. KG-BERT is a state-of-the-art method for triple classification tasks. The main idea behind it is to represent the KG triples as text, using their labels to create a lexicalization in natural language and gather contextual sentences from a corpus. This text can then be used to fine-tune the existing pre-trained BERT embeddings, for a classification task. As part of this lexicalization, we explored a set of equivalent ways to represent the notion of hyponymy. In our cases, where we had access to a large corpus is a concept of gave the best performance for the model for OmniScience and is a for UMLS.
The format of the model’s input is as follows: each of the triple elements is separated by the [SEP] token, and at the beginning of the input a [CLS] token is added. Each entity name, as well as the relation’s textual description is tokenized. An example of such a representation for the text "Linear Algebra is a concept of Mathematics" is: [CLS] linear algebra [SEP] is a concept of [SEP] mathematics [SEP]. In the case of the absence of words in the vocabulary, the model is considering their sub-words and is adding specified tokens for the missing parts of the sentence. Cross-entropy is used as a loss function. For our research, we used the code3 provided by the authors as a basis. We obtained good performance with "bert-base-uncased" BERT base.
Experiments
WordNet and UMLS were trained using is a as relation phrase, and OmniScience branches were trained with is a concept of. All of the models were trained using random seed equal to 42, and bert-base-uncased as a BERT base. See below the table with the results:
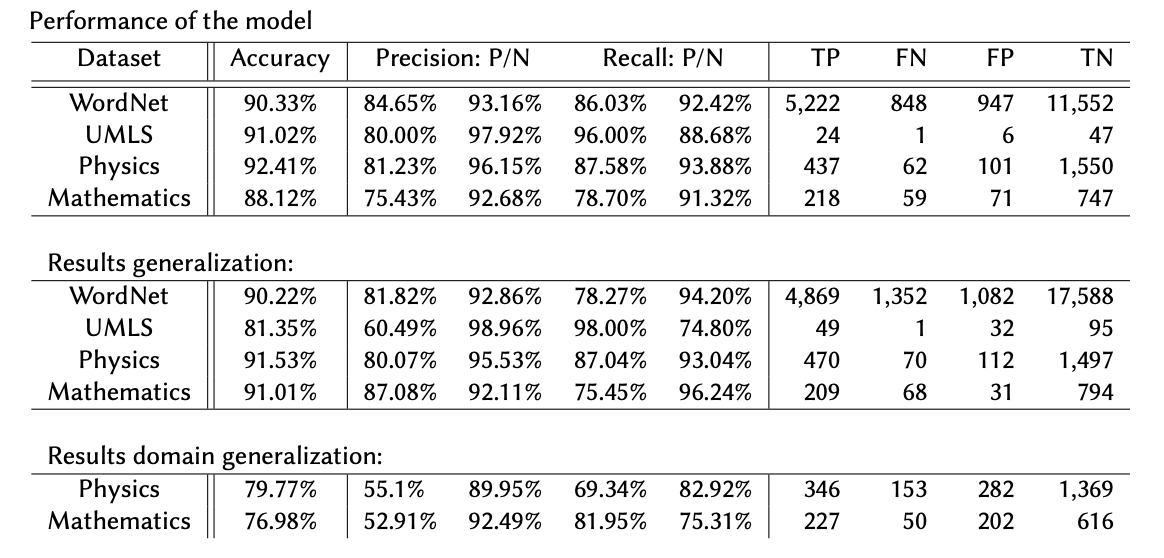
Experiments: Performance KG-BERT for different hierarchical Knowledge Graphs
We note a high (>88%) accuracy for all of the KGs, and also high scores for all the metrics selected by us as important (Pp and Rn). OmniScience’s Physics Branch evaluation gets the highest scores, while the Mathematics Branch gets the lowest for that experiment.
Experiments: Model generalization to fully unseen triples
We investigated the model’s ability for generalizing on unknown data. We performed two experiments: the first of them (generalization), applied to all four datasets, uses the second split of data reported in Table 4, and the second sampling approach described in subsection 3.3; the second experiment (domain generalization) tested specifically whether a model trained on one OmniScience branch could be applied to another branch. We tested the model trained on one branch with the test set generated for the other branch, for both branches.
Again, we note a high (>90%) accuracy in the generalization experiments for all of the KGs, except from UMLS dataset, where the accuracy is equal to 80%. We discuss the performance on UMLS further in the Discussion section. The Physics Branch classification result gets the highest accuracy score, but the Mathematics Branch achieved the highest scores in independent values for Pp and Rn.
The results for the domain generalization experiment that tested how a model trained on the Mathematics branch of OmniScience performed when classifying examples from the Physics branch (and another way round) are as follows: 80% accuracy for Physics branch being a test set, and 77% for Mathematics branch. Pp is equal to 55% and 53% accordingly, and Rn is equal to 83% and 75%. Even if the accuracy score and Rn are relatively high, we note the low ability of the model to properly classify positive examples (Pp equal to 53-55% in both cases). This means that a model should be trained per domain for a better performance.
Experiments: Prediction of long-distance hierarchy using the model
We carried out an experiment to check whether the model can predict a hierarchical relationship between concepts further apart in the hierarchical structure. We created some datasets with triples containing concepts at different levels or hierarchical depth (different hop-levels). As a point of terminology, given the two triples Optics is a concept of Physics and Fiber Optics is a concept of Optics, we consider the triple Fiber Optics is a concept of Physics a 2-hop triple.
For all of the datasets, scores such as accuracy, Pp, and Rn are decreasing with the increase of hop distance. For Pp the decrease is substantial in every dataset (20-30% decrease). For WordNet Pp decreased to 51% for the 2-hop triples, for Physics to 68%, and for Mathematics Branch Pp decreased to 45%. Rn decreased less suddenly (5-8%). For 3-hop, 4-hop, and pairs with more concepts in-between Pp and Rn continued to decrease. This shows that our model performs well to predict a direct hypernym relationship, but not for hypernym at more than one hop distance.
Discussion
Performance scores across the selected metrics for QA are high (Precision for positive triples and Recall for negative triples). For every dataset, we noted an accuracy score above 88%. Accuracy for the generalization experiment, where we wanted to see how the model can deal with examples that it did not use for training, yielded decent results (accuracy above 80%). However, testing a model build on one OmniScience branch on another scientific domain of the same KG did not give accurate results. Therefore, the model can generalize well, but needs to be trained per domain.
The reproducibility of the method tested here is a strong point: we showed that this approach can be used on four very different datasets used in different research contexts. However, the accuracy for the UMLS dataset was not as high as the others. The main reason for the lack of performance is the small size of the sample. We further investigated the converge of the model, and concluded that for OmniScience’s Physics and Mathematics datasets, the model started to learn with around 1.7k examples. Moreover, for the Physics branch we noted good results from 6.8k training examples (40% of the data), and for Mathematics branch from around 5.6k (65 % ofthe data). These proportions should be taken into consideration when applying our method.
Our recommendation on how to prepare the model for hierarchy evaluation is as follows:
- the model should be trained per domain,
- relation sentence (or lack of it) could be selected as one of the hyperparameters, and used for the models’ optimization,
- proper negative sampling strategy should be selected, the one that can be the most representative strategy of the possible errors in the KGs,
-
depending on the scientific domain, different BERT bases could be selected (e.g. bioclinical-bert or sci-bert could be used for KGs in the medical or biological domain)
Final remarks
Thank you for reaching out to the end of this post! I copy-pasted most of the things, but the paper is quite short so I think trying to simplify it would be a bit too much haha. I also didn't include here any referenes, so please feel free to have a look into the paper!
Do let me know if you have any questions! :)
Besitos, szarki9
